
※ 마이크로소프트웨어 401호에 게재된 기고문입니다.
4차 산업혁명의 핵심 키워드 ‘클라우드’는 불과 얼마 전까지만 하더라도 점진적인 IT 메가 트렌드 정도로만 여겨졌다. 하지만 기업은 코로나19 국면 이후 비즈니스 연속성을 유지하기 위해 조속한 클라우드 도입을 고려할 수밖에 없게 됐다. 코로나 19가 오프라인에서 이뤄지던 대면 접촉의 상당수를 디지털 환경으로 옮겨 놓았고, 그로 인해 데이터 통신이 급격하게 증가했기 때문이다.
그러나 무작정 모든 워크로드를 클라우드로 이전할 수는 없는 법. 각 기업의 시스템 요구사항을 정확히 파악하지 못한 채 성급히 마이그레이션을 진행할 경우 오히려 시스템을 유지/보수하는 데 드는 총비용이 증가하게 된다. 따라서 기업의 워크로드를 클라우드에 마이그레이션하기 전에 먼저 클라우드 도입 적합성을 꼼꼼히 따져보고, 그에 걸맞은 최적의 아키텍처를 고민하는 등 치밀한 설계 과정을 거쳐야 한다.
슬기로운 클라우드 생활을 영위함으로써 코로나19發 클라우드 패러다임에 한 걸음 더 다가가기 위해 기업이 무엇을 대비해야 하는지 필자가 경험한 몇 가지 경우를 통해 이야기해보려 한다.
오징어 대란을 통해 본 트래픽 로드밸런싱
‘확장성’과 ‘유연성’이라는 클라우드의 장점이 충분히 발휘되기 위해서는 적절한 부하 분산이 뒷받침되어야 한다. 규모 있는 트래픽을 처리하기 위해 어떻게 클라우드 시스템 아키텍처를 설계해야 하는지 얼마 전 겪은 ‘오징어 대란’ 경우를 들어 설명하고자 한다.
3월 말, 강원도지사의 SNS 홍보에서 비롯된 ‘감자 대란’에 이어 하루 동안 진행한 동해 오징어 판매 이벤트는 또 다른 대란을 불러왔다. 해당 상품이 쇼핑몰에 오픈된 직후인 오전 9시, 트래픽 폭주로 인해 서버가 다운됐다. 당시 이벤트를 진행했던 쇼핑몰은 호스팅 기반의 웹 서비스로 운영되고 있어 갑작스럽게 폭증하는 트래픽에 유연하게 대처하기 어려웠다.
따라서 쇼핑몰을 클라우드 서버(Virtual Machine, 이하 VM)로 재구성했고, 또다시 폭주할 트래픽에 대비해 인스턴스를 14대까지 증설했다.
‘감자 대란’을 이미 겪은 터라 14대의 가상서버(VM)로 확장하는 데 약 한 시간 남짓 소요됐다. 그러나 이마저도 과도한 트래픽으로 재 오픈 직후 다시 서비스가 다운되었고, 총 18대의 VM으로 오후 4시, 서비스를 재개했다.
그러나 서비스를 재개한 지 몇 분 지나지 않아 데이터베이스 서버상의 또 다른 과부하로 인해 간헐적인 서비스 중단이 발생했다. 입출력 성능을 향상시키기 위해 데이터베이스 서버 사양을 상향 조정했고, 디스크 또한 기존 HDD(Hard Disk Drive)기반에서 SSD(Solid State Drive)로 전환했다. 발 빠른 서버 자원 확장 덕택에 오후 5시 45분, 준비된 물량 전체를 소진한 뒤 이벤트를 정상적으로 종료할 수 있었다.
클라우드의 경우 웹 호스팅과 달리 원하는 성능과 용량의 인스턴스를 선택해 단 몇 분 안에 서버를 구축할 수 있다. 더 나아가 필요에 따라 이렇게 생성된 인스턴스를 복제해 빠르게 증설하고 회수할 수 있다. 레거시 인프라에서는 찾아보기 어려운 탄력적 자원 운용과 빠른 서비스 전개다.
여기서 중요한 것은 인스턴스를 생성하고, 서비스에 적합한 형태로 미리 시스템 구성을 완료해둬야 한다는 점이다. 그래야만 유사시에 필요에 따라 워크로드를 처리할 VM 을 자유자재로 증설하고 또 회수할 수 있기 때문이다.
오징어 대란 시스템 아키텍처 변화
오징어 대란 당시 시스템 아키텍처의 변화는 <그림 1,2,3>과 같다.
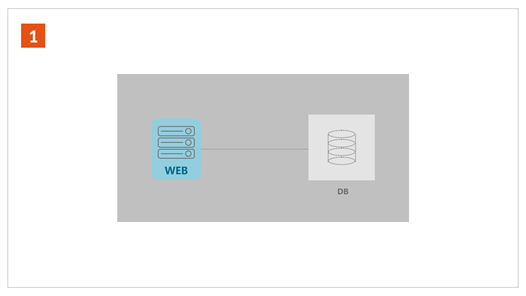
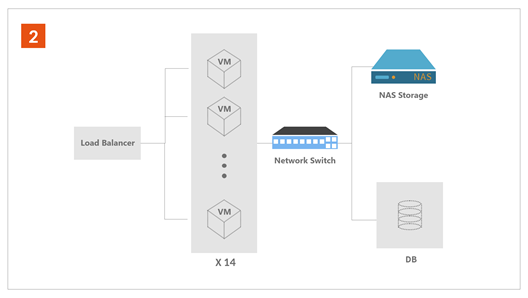
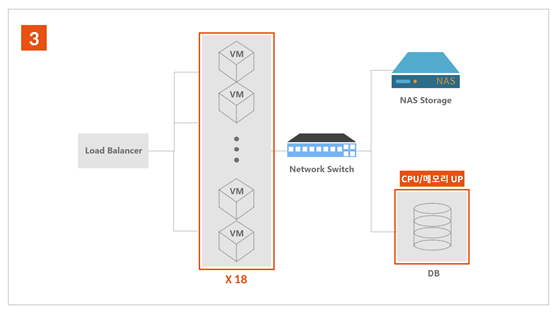
최종 구성도
최종 구성도는 <그림 4>다. 웹 호스팅만을 단독으로 사용하던 최초 인프라 구성에서 VM을 18대로 확장하고, 데이터베이스 서버 사양을 상향 조정하는 데까지 걸린 시간은 반나절이 채 되지 않았다. 만일 이벤트를 진행하기 이전에 성능 측정 테스트를 통해 시뮬레이션했다면, 최종 구성도와 같은 아키텍처로 이벤트 부하 분산을 원활하게 진행할 수 있었을 것이다. 최종적으로 이벤트를 진행한 아키텍처의 각 파트를 살펴보자. 크게 4가지로 나누어 볼 수 있다.
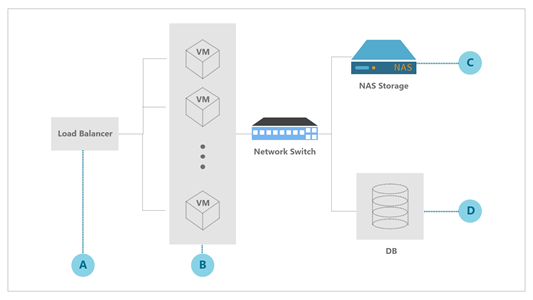
A. 부하 분산 로드밸런서
당시 서비스 연결 방식은 로드밸런서의 간섭을 최소화하는 방식으로 다량의 연결 처리를 가능케 하는 TCP 타입이었다. 트래픽 분배 방식은 일단 서버와 연결이 맺어진 후 요청에 대해 동일한 서버에서 응답할 수 있도록 소스 해싱(Source hashing) 방식을 채택했다.
B. 가상머신(VM)
해당 시스템에 BMT(Benchmarking Test, 성능측정)를 진행한 결과 VM 한 대당 2,000명가량의 동시 접속분을 처리할 수 있는 것으로 파악됐다. 최초 대응 시 2만 8천 명이 동시 접속할 수 있도록 14개의 인스턴스를 생성했으나, 예상보다 더 많은 접속량으로 인해, 최종 18대의 VM으로 서비스를 정상화했다.
C. 네트워크 스토리지(NAS, Network Attached Storage)
대용량 이미지 파일의 경우 별도의 네트워크 스토리지나 CDN(Contents Delivery Network, 콘텐츠 전송 네트워크)을 적극 활용해 파일 전송으로 인한 부하를 분산시키는 것이 더 효과적이다. 해당 쇼핑몰은 시스템 구성상 별도의 네트워크 스토리지를 두고 용량이 큰 파일을 분산하고 있어서 예상보다 큰 네트워크 과부하에도 빠른 대처가 가능했다.
D. 데이터베이스 부하 분산
이 경우 로드밸런서가 다수의 요청을 정상적으로 분배할 수 있는 상황이 되었음에도, 데이터베이스 단으로 트래픽이 과도하게 몰려 연속성 있는 서비스를 운영하는 데 어려움을 겪었다. 접속자수가 현저히 늘어날 것이 명확하다면, 트래픽 분산 및 서버 증설 못지않게 사전에 데이터베이스 서버 성능분석을 진행해 적절한 시스템 구성을 완료해두는 것 또한 중요하다.
*트래픽 부하 분산 Tip
- 가상서버(VM) 이미지 Warm-up
짧은 시간에 트래픽 폭증이 예상되는 이벤트를 앞두고 있다면, 서비스가 가능한 상태의 가상서버(VM)를 생성해 유사시 바로 활용할 수 있도록 사전에 Warm-up을 해둬야 한다. 그래야만 이슈 발생 시 즉각적으로 자원을 확장할 수 있기 때문이다. 트래픽이 이미 터진 후에 이미지를 복제하려 한다면 대응이 그만큼 느려질 수밖에 없다. 또, 로드밸런서와 오토스케일링으로 대처할 수 없는 수준의 트래픽이 유입될 가능성도 염두에 둬야 한다. - 사전 성능측정테스트(BMT)를 통한 시뮬레이션
서비스 규모에 맞는 트래픽을 사전에 예측하고, 시스템의 응답성과 안정성을 검증하는 성능측정테스트(BenchMark Test, 이하 BMT)는 실제 서비스를 운영하기에 앞서 필수적으로 요구된다. 시스템이 최초 설계 의도에 맞게 부하를 견딜 수 있는지, 시스템이 과부하 상태에서도 안정적으로 서비스를 제공할 수 있는지를 사전에 검증해야 중단 없는 서비스 제공이 가능해지기 때문이다.
성능측정은 먼저 서비스의 규모와 목적을 명확히 하고, 해당 서비스를 이용하는 고객을 중심으로 테스트 시나리오를 작성하는 데서 출발한다. 이후 부하 발생기로 인위적인 부하를 발생해 시스템 전반의 성능을 측정한다. 측정을 진행하다 보면, 네트워크나 데이터베이스, 미들웨어 및 인프라 각 모듈에서 병목 현상이 발견된다. 정확히 어느 구간에서 병목 현상이 발생하는지 분석하는 프로파일링(Profiling) 과정을 거친 후, 해당 구간을 개선해 다시 테스트를 진행하는 과정을 반복한다. 이와 같은 과정을 통해 시스템이 목적대로 기능할 수 있도록 준비해야만 예측한 서비스의 품질을 일정하게 유지할 수 있다.
- CDN을 활용한 정적 파일 분산
이미지나 동영상 등 용량이 큰 파일을 서비스하는 경우 웹서버가 직접 응답을 해주는 것보다 미리 CDN을 통해 콘텐츠를 전송하도록 부하를 분산하는 것이 효율적이다. 그렇지 않고 대용량 콘텐츠를 원본 서버(웹서버)에 둔다면 서버가 클라이언트의 요청에 일일이 응답해야 하기 때문에 트래픽 부하 발생을 막을 수 없다.
- 컨설팅 및 모니터링
실제 서비스 오픈 후 트래픽뿐만 아니라 시스템 전반에 걸친 모니터링이 필수적이다. 그래야만 시스템이 정상적으로 운영되는지 실시간 확인이 가능하고, 이를 바탕으로 이슈 발생 시 발 빠른 대처와 서비스 정상화가 가능하기 때문이다. 최초 구축 시 기존 인프라를 분석하고 최적의 아키텍처를 설계하는 컨설팅 과정 또한 매우 중요하다. 최적화된 설계가 뒷받침되어야만 클라우드의 장점을 온전히 활용할 수 있기 때문이다.

가비아 클라우드IDC팀에서 클라우드 컨설팅 및 기술지원 업무를 맡고 있는 14년 차 서버 엔지니어입니다.
‘클라우드 서버를 안 써본 사람은 있어도 한 번 써본 사람은 없다!’
그 무엇을 고민하든 결국 답은 클라우드라고 생각합니다.
클라우드 도입 컨설팅이 필요하신가요?
20년 인프라 운영 경험으로 체계적인 클라우드 서비스를 구축한
가비아 클라우드 전문가가 직접 상담해 드립니다.
무료 컨설팅 신청하기 02-3473-3911 / gabia.cloud



