
이번 글에서는 Python의 BeautifulSoup, requests 패키지를 이용하여, 가비아 라이브러리 홈페이지의 게시글들을 파싱하는 방법을 소개합니다.
들어가기 전
본문으로 들어가기 전, 먼저 크롤링(Crawling), 파싱(Parsing), 스크래핑(Scraping)에 대한 정의를 알아보겠습니다.
웹 크롤러 (Web crawler)
” A Web crawler, sometimes called a spider or spiderbot and often shortened to crawler, is an Internet bot that systematically browses the World Wide Web, typically for the purpose of Web indexing (web spidering). ” (출처: wikipedia)
크롤링은 웹 인덱싱을 위해 WWW를 체계적으로 탐색해나가는 것을 의미합니다. 크롤러가 하는 행위(WWW를 탐색해나가는 행위 등)를 바로 ‘크롤링’ 이라고 합니다.
파싱 (Parsing)
” Parsing, syntax analysis, or syntactic analysis is the process of analyzing a string of symbols, either in natural language, computer languages or data structures, conforming to the rules of a formal grammar. ” (출처: wikipedia)
웹 파싱은 웹 상의 자연어, 컴퓨터 언어 등의 일련의 문자열들을 분석하는 프로세스입니다.
웹 스크래핑 (Web scraping)
” Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. ” (출처: wikipedia)
웹 스크래핑은 다양한 웹사이트로부터 데이터를 추출하는 기술을 의미합니다.
정의를 살펴보면, 흔히 사용되는 용어 ‘크롤러’는 데이터 추출의 의미보다 웹 사이트를 탐색하고, 인덱싱 하는 것에 더 중점적인 의미를 갖고 있는 것 처럼 보입니다. 따라서 이번 글 에서는 ‘웹 크롤링’ 이라는 단어의 사용보다 ‘웹 파싱’ 이라는 단어를 사용하겠습니다. (각각의 용어에 대한 해석은 다를 수 있습니다.)
웹 파싱해보기
파이썬에서 가장 많이 사용되고 있는 패키지 BeautifulSoup, Requests를 사용하여 웹 사이트를 파싱해보겠습니다.
1. BeautifulSoup, Requests 패키지가 설치되었는지 확인합니다.
pip list목록에 beautifulsoup4 , requests 패키지가 없다면 설치해줍니다.
pip install beautifulsoup4
pip install requestsBeautifulSoup: 웹 페이지의 정보를 쉽게 스크랩할 수 있도록 기능을 제공하는 라이브러리입니다.
Requests: HTTP 요청을 보낼 수 있도록 기능을 제공하는 라이브러리 입니다.
2. 파싱을 진행할 페이지를 분석합니다.
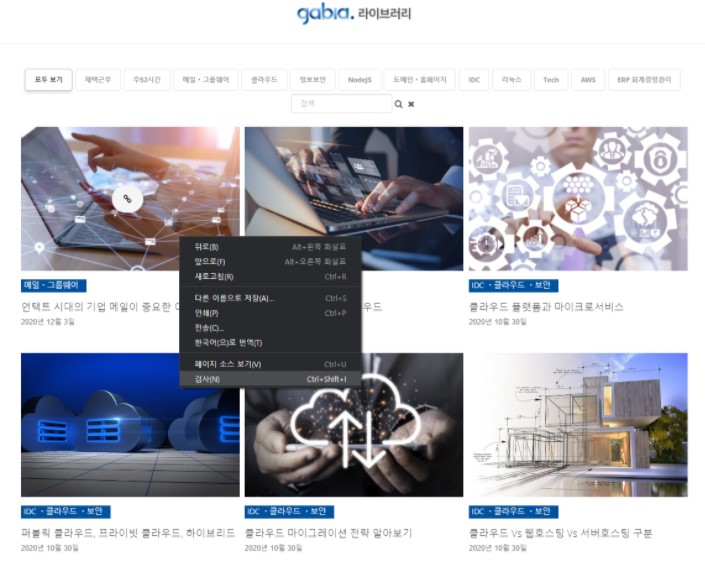
1. 가비아 라이브러리 홈페이지에 접속합니다.
2. 홈페이지에 접속하여 HTML 소스를 분석합니다.
크롬 브라우저 기준, F12 혹은 마우스 우클릭 > '검사'를 클릭하면 ‘개발자 도구 창’ 이 나타납니다.
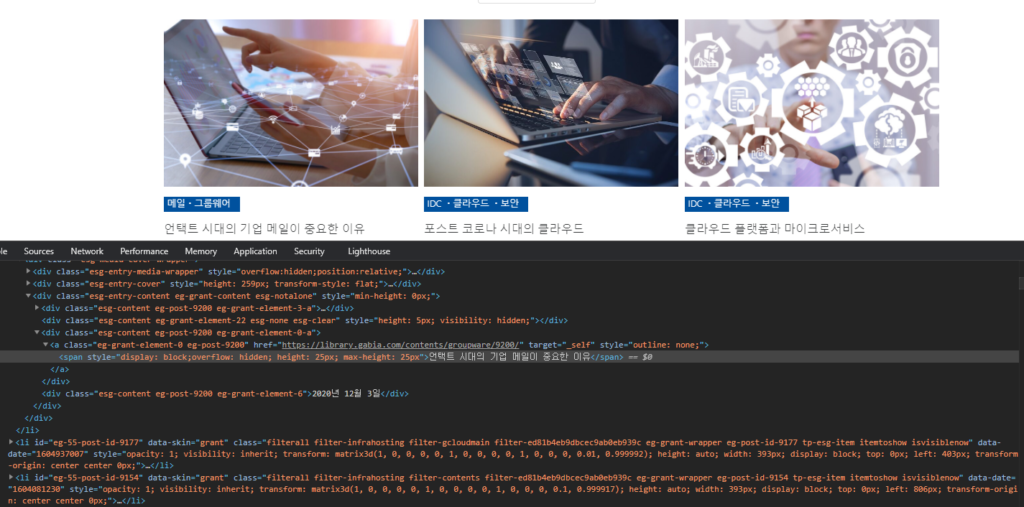
HTML 소스를 살펴보면 게시글들의 제목, 링크, 날짜 등의 내용을 확인할 수 있습니다.
3. 파싱을 위해 파이썬 파일을 생성합니다.
vi parser.py4. 파싱을 위한 코드를 작성하고 실행시킵니다.
4-1. 가비아 라이브러리 홈페이지에 존재하는 포스터들의 제목을 추출해봅니다.
import requests
from bs4 import BeautifulSoup as bs
page = requests.get("https://library.gabia.com/")
soup = bs(page.text, "html.parser")
elements = soup.select('div.esg-entry-content a > span')
for index, element in enumerate(elements, 1):
print("{} 번째 게시글의 제목: {}".format(index, element.text))line 1 ~ 2: 필요한 라이브러리(requests, beautifulsoup)를 import 합니다.
line 4: requests 를 이용하여 ‘https://library.gabia.com’ 주소로 get 요청을 보내고 응답을 받습니다. 상태 코드와 HTML 내용을 응답받을 수 있습니다.
line 5: 응답받은 HTML 내용을 BeautifulSoup 클래스의 객체 형태로 생성/반환합니다. BeautifulSoup 객체를 통해 HTML 코드를 파싱하기 위한 여러 가지 기능을 사용할 수 있습니다. (response.text는 응답 받은 내용(HTML)을 Unicode 형태로 반환합니다.)
line 7: BeautifulSoup 가 제공하는 기능 중 CSS 셀렉터를 이용하여 원하는 정보를 찾을 수 있는 기능입니다. (div.esg-entry-content a > span 은 esg-entry-content 클래스로 설정된 div 태그들의 하위에 존재하는 a 태그, 그 하위에 존재하는 span 태그를 의미합니다.) 이 셀렉터를 이용하면 가비아 라이브러리 홈페이지에 존재하는 포스터들의 제목을 추출할 수 있습니다.
아래와 같이 실행 결과를 확인할 수 있습니다.
$ python parser.py
1 번째 게시글의 제목 : 언택트 시대의 기업 메일이 중요한 이유
2 번째 게시글의 제목 : 포스트 코로나 시대의 클라우드
3 번째 게시글의 제목 : 클라우드 플랫폼과 마이크로서비스
4 번째 게시글의 제목 : 퍼블릭 클라우드, 프라이빗 클라우드, 하이브리드 클라우드
5 번째 게시글의 제목 : 클라우드 마이그레이션 전략 알아보기
6 번째 게시글의 제목 : 클라우드 vs 웹호스팅 vs 서버호스팅 구분
7 번째 게시글의 제목 : 마이데이터란 무엇인가
8 번째 게시글의 제목 : 클라우드에 저장된 개인정보, 어떤 문제가 있을까
9 번째 게시글의 제목 : 클라우드 컴퓨팅의 종류, SaaS란?
...4-2. 가비아 라이브러리 홈페이지에 존재하는 포스터들의 제목과 링크를 동시에 추출해봅니다.
import requests
from bs4 import BeautifulSoup as bs
page = requests.get("https://library.gabia.com/")
soup = bs(page.text, "html.parser")
elements = soup.select('div.esg-entry-content a.eg-grant-element-0')
for index, element in enumerate(elements, 1):
print("{} 번째 게시글: {}, {}".format(index, element.text, element.attrs['href']))line 7: esg-entry-content 클래스로 설정된 div 태그들의 하위에 존재하는 태그 중, eg-grant-element-0 클래스를 갖는 a 태그만을 추출합니다.
line 10: link.text 추출한 a 태그 안에 존재하는 text 내용을 추출합니다. link.attrs['href'] a 태그의 href 속성의 값을 추출합니다.
아래와 같이 실행 결과를 확인할 수 있습니다.
$ python example_crawling_gabia_library2.py
1 번째 게시글: 언택트 시대의 기업 메일이 중요한 이유, https://library.gabia.com/contents/groupware/9200/
2 번째 게시글: 포스트 코로나 시대의 클라우드, https://library.gabia.com/contents/infrahosting/9177/
3 번째 게시글: 클라우드 플랫폼과 마이크로서비스, https://library.gabia.com/contents/infrahosting/9154/
4 번째 게시글: 퍼블릭 클라우드, 프라이빗 클라우드, 하이브리드 클라우드, https://library.gabia.com/contents/infrahosting/9147/
5 번째 게시글: 클라우드 마이그레이션 전략 알아보기, https://library.gabia.com/contents/infrahosting/7705/
6 번째 게시글: 클라우드 vs 웹호스팅 vs 서버호스팅 구분, https://library.gabia.com/contents/infrahosting/9118/
7 번째 게시글: 마이데이터란 무엇인가, https://library.gabia.com/contents/infrahosting/9142/
8 번째 게시글: 클라우드에 저장된 개인정보, 어떤 문제가 있을까, https://library.gabia.com/contents/infrahosting/9136/
9 번째 게시글: 클라우드 컴퓨팅의 종류, SaaS란?, https://library.gabia.com/contents/infrahosting/9123/
...5. 파싱한 데이터를 활용해봅니다.
이번엔 Pandas, openpyxl 패키지를 이용하여 파싱한 데이터를 엑셀 형태로 변환해보겠습니다.
5-1. Pandas, openpyxl 패키지가 설치되어 있는지 확인합니다.
pip show pandas
pip show openpyxl패키지가 설치되어 있지 않다면 설치해줍니다.
pip install pandas
pip install openpyxlPandas: 데이터를 쉽게 분석하고 조작할 수 있는 파이썬의 라이브러리입니다.
openpyxl: 엑셀 파일을 읽고 작성할 수 있는 파이썬 라이브러리입니다.
5-2. 위에서 작성한 코드를 아래와 같이 수정합니다.
import requests
from bs4 import BeautifulSoup as bs
import pandas as pd
page = requests.get("https://library.gabia.com/")
soup = bs(page.text, "html.parser")
elements = soup.select('div.esg-entry-content a.eg-grant-element-0')
titles = []
links = []
for index, element in enumerate(elements, 1):
titles.append(element.text)
links.append(element.attrs['href'])
df = pd.DataFrame()
df['titles'] = titles
df['links'] = links
df.to_excel('./library_gabia.xlsx', sheet_name='Sheet1')line 3: pandas 라이브러리를 import합니다.
line 1 ~ 14: 이전에 작성한 코드와 동일합니다. 다만, 이번에는 게시글의 제목, 링크를 출력하지 않고 각각의 배열에 값을 추가합니다.
line 17 ~ 19: titles 배열과 links 배열의 값으로 Pandas의 DataFrame 을 생성합니다.
line 21: DataFrame 의 to_excel() 함수를 이용하여 엑셀파일을 작성합니다.
아래와 같이 생성된 엑셀 파일을 확인할 수 있습니다.
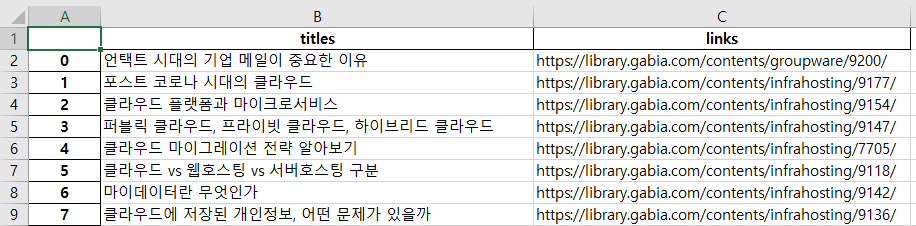
지금까지 가비아 Python 호스팅 환경에서 가비아 라이브러리 홈페이지를 파싱하는 방법을 알아보았습니다.
가비아는 초보 개발자도 쉽게 호스팅 서비스를 이용할 수 있도록 최적화된 호스팅 환경을 제공합니다.
또한 CBT, OBT를 거쳐 검증된 컨테이너 기반의 환경에 Python 호스팅 서비스를 제공해 때문에 안정적이고, 믿을 수 있습니다.
가비아 Python 호스팅을 이용해 이번 포스팅과 같이 웹 파싱을 개발해 보시기 바랍니다.
[가비아 Python 호스팅 알아보기]