
AI가 더 이상 낯설지 않은 요즘, 여러분은 어떤 모델을 사용하고 계신가요?
이제는 ChatGPT뿐 아니라 Gemini, Claude 등 다양한 모델이 함께 주목받고 있습니다. 최근에는 DeepSeek처럼 오픈소스 기반 모델까지 등장하면서, 선택의 폭은 더욱 넓어졌죠. 하지만 기술이 아무리 발전해도, 결국 사용자에게 중요한 건 하나입니다. 바로 ‘내 업무에는 어떤 AI가 가장 잘 맞을까?’를 판단하는 일입니다. 🤔
그래서 이번 글에서는 ChatGPT, Gemini, Claude 세 모델을 다양한 업무 상황에 적용해 테스트해 봤습니다. 개념 설명, 번역 등 실무에서 자주 쓰는 작업을 중심으로 성능을 비교했는데요. 과연, 각 작업에 가장 잘 맞는 AI 모델은 무엇이었을까요? 지금 테스트 결과를 확인해 보세요. 👀✨
✅ ChatGPT, Gemini, Claude는 어떤 모델인가요?
본격적인 테스트 전에, 각 AI 모델이 어떤 배경과 특징을 가졌는지 정리해 보았습니다.
| 구분 | ChatGPT | Gemini | Claude |
|---|---|---|---|
| 개발사 | OpenAI | Google DeepMind | Anthropic |
| 목표 | 대중성과 실용성을 갖춘대화형 AI | 구글 서비스와 실시간으로 연동되는 업무용 AI | 윤리 기준에 따라 스스로 판단하는 헌법형 AI |
| 응답 방향성 | 대화 흐름이 자연스럽고, 사용자에게 친화적인 응답 | 텍스트·이미지 등 다양한 입력을 이해하고, Gmail·Docs 등과의 연동 작업을 지원하는 응답 | 사전에 정의된 윤리 기준을 기반으로, 신중하고 책임감 있게 판단한 응답 |
| 대표 요금제 (*25년 5월 기준) | Plus $20/월 | Advanced ₩29,000/월 | Pro $17/월 |
✅ 모델뿐만 아니라, ‘버전’도 중요한 이유는 무엇일까요?
ChatGPT, Gemini, Claude는 각기 다른 철학과 응답 방향성을 지닌 AI입니다. 하지만 같은 모델이라도 버전에 따라 성능과 특성이 달라질 수 있다는 점을 함께 고려해야 합니다. 예를 들어, 글쓰기에는 GPT-4.5와 Claude 4 Sonnet이, 수학·코딩 작업에는 OpenAI o3와 Claude 4 Opus와 같은 모델이 더 적합하죠. 따라서 AI를 선택할 때는 모델뿐 아니라, 업무 목적에 최적화된 ‘버전’까지 고르는 것 또한 중요합니다. 이번 테스트에서도 이러한 점을 반영해, GPT-4.5, Gemini 2.5 Pro, Claude Sonnet 4를 기준으로 성능을 비교했습니다.
✅ 테스트는 어떤 기준으로 평가했을까요?
총 6가지 실무 상황을 선정하고, 동일한 조건에서 세 모델이 각각 어떻게 응답하는지 비교해 보았습니다. 공정한 비교를 위해 GPT, Gemini, Claude 세 모델을 동일한 조건에서 사용할 수 있는 ‘가비아 AI채팅’ 플랫폼을 활용했습니다. 가비아 AI채팅은 세 모델의 최신 프리미엄 버전을 한 곳에서 전환하며 사용할 수 있어, 테스트 환경으로 적합했습니다.
응답 결과는 다음 네 가지 기준으로 평가했습니다.
• 정확성 – 요청에 명확하게 응답했는가, 정보가 신뢰할 수 있는가
• 창의성 – 정형화된 답을 넘어서 독창적인 시각이나 표현이 있었는가
• 전달력 – 문장 구조, 내용 흐름이 자연스럽고 이해하기 쉬웠는가
• 실용성 – 결과물이 수정 없이 실무에 바로 활용 가능한가
이번 테스트는 단순한 스펙 비교를 넘어, 실제 업무 환경에서 각 모델이 얼마나 실용적인 결과를 낼 수 있는지에 초점을 맞췄습니다. 그 과정에서 각 모델의 예상 밖의 강점과 아쉬운 점도 함께 발견할 수 있었는데요. 지금부터 그 결과를 함께 살펴보겠습니다. 🚀
✅ 실제 테스트에서는 어떤 결과가 나왔을까요?
1. 테스트 주제 : 개념 설명
개념 설명은 AI에게 자주 요청되는 작업 중 하나입니다. 실제 업무에서도 복잡한 기술 개념을 쉽고 명확하게 전달하는 능력은 매우 중요한데요. 이번 테스트에서는, AI가 개념을 얼마나 정확하게 설명하는지, 또 어떤 방식으로 정보를 구조화하는지를 평가했습니다.
✔ 프롬프트 : “클라우드는 무엇인가요? 7살 아이에게 클라우드 개념을 설명해주세요.”
✔ 모델별 응답

✔ 평가 결과 (항목별 10점 만점 기준)
| 구분 | ChatGPT | Gemini | Claude |
|---|---|---|---|
| 정확성 | 8 | 9 | 8 |
| 창의성 | 7 | 10 | 8 |
| 전달력 | 8 | 9 | 9 |
| 실용성 | 8 | 9 | 10 |
| 총점 | 31점 | 37점 | 35점 |
🏆 가장 우수한 답변: Gemini
• 정확성 : Gemini는 ‘마법 주머니’라는 비유를 사용해 클라우드 개념을 쉽고 명확하게 설명했습니다. ChatGPT는 ‘마법 상자’라는 표현이 직관적이긴 했지만, 설명이 다소 부족했습니다. Claude는 말투는 친절했으나, 정보 전달력 면에서는 아쉬움이 있었습니다.
• 창의성 : Gemini는 다양한 비유를 활용해 개념을 독창적으로 설명했습니다. Claude의 ‘마법의 보관함’이라는 표현도 인상적이었습니다. 반면, ChatGPT는 전체적으로 평이한 표현을 사용했습니다.
• 전달력 : Gemini는 아이의 시선에 맞춘 표현으로 몰입감 있게 전달했습니다. Claude는 글 구성은 안정적이었지만, 문장이 자주 끊겨 흐름이 다소 어색했습니다. ChatGPT는 전반적으로 전달 흐름이 단조로웠습니다.
• 실용성 : Gemini는 유아용 콘텐츠로도 활용이 가능할 만큼 완성도가 높았습니다. Claude는 문단 구성은 괜찮았지만, 일부 표현은 보완이 필요했습니다. ChatGPT는 전반적으로 수정이 많이 필요한 수준이었습니다.
2. 테스트 주제 : 요점 요약
요점 요약 역시 실무에서 자주 활용되는 기능 중 하나입니다. 긴 문서의 핵심을 빠르게 파악할 수 있도록 돕는 만큼, 정보를 얼마나 간결하게 압축하고, 구조화하느냐가 중요한 기준이 됩니다. 이번 테스트에서는 AI의 요약 정확도, 정보 압축력, 그리고 전체적인 구성 완성도를 중심으로 비교했습니다
✔ 프롬프트 : “해당 기사*의 주요 내용을 요약하세요. 5문장 이내로 요약하세요.”
*기사 출처 : https://www.donga.com/news/It/article/all/20241105/130366409/1
✔ 모델별 응답
✔ 평가 결과 (항목별 10점 만점 기준)
| 구분 | ChatGPT | Gemini | Claude |
|---|---|---|---|
| 정확성 | 9 | 10 | 9 |
| 창의성 | 7 | 8 | 7 |
| 전달력 | 8 | 9 | 8 |
| 실용성 | 8 | 10 | 9 |
| 총점 | 32점 | 37점 | 33점 |
🏆 가장 우수한 답변: Gemini
• 정확성 : Gemini는 기사의 핵심 정보를 빠짐없이 담았습니다. ChatGPT는 주제는 정확했지만, 내용이 지나치게 생략되었습니다. Claude는 표현은 명확했으나, 기사의 내용을 다소 일반화됐습니다.
• 창의성 : Gemini는 항목별 정리로 글 구성에 차별성이 있었습니다. ChatGPT와 Claude는 평이한 문단 요약에 그쳤습니다.
• 전달력 : Gemini는 문장이 자연스럽고 가독성이 뛰어났습니다. Claude는 전체적으로 글은 매끄럽지만 다소 건조했고, ChatGPT는 흐름은 좋았으나 요약이 과해 의미 전달이 약해졌습니다.
• 실용성 : Gemini는 실무에 바로 활용할 수 있을 만큼 완성도가 높았습니다. 이에 비해, Claude는 일부 표현 보완이 필요했고, ChatGPT는 전반적인 보완이 필요해 보였습니다.
3. 테스트 주제 : 번역
번역은 단순한 직역을 넘어, 문화적 맥락과 비유적 의미까지 정확히 이해하고 전달하는 작업입니다. 속담은 시대적 가치관과 사고방식을 담고 있어, 이를 국내 문화와 비교하며 해석하는 능력이 필요합니다. 이에 따라 이번 테스트에서는 속담 번역을 요청하여, 의미 전달의 정확성, 맥락 이해도, 표현의 자연스러움 등을 평가했습니다.
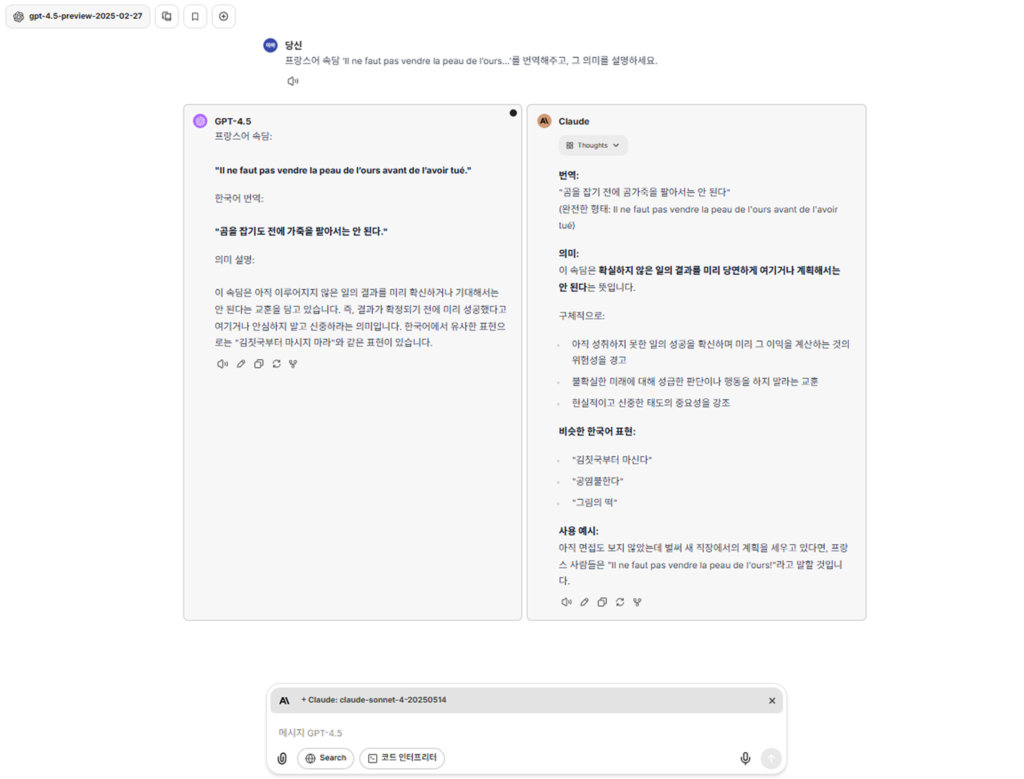
✔ 프롬프트 : “프랑스어 속담 ‘Il ne faut pas vendre la peau de l’ours avant de l’avoir tué.’를 번역해 주고, 그 의미를 설명하세요.”
✔ 모델별 응답

✔ 평가 결과 (항목별 10점 만점 기준)
| 구분 | ChatGPT | Gemini | Claude |
|---|---|---|---|
| 정확성 | 8 | 10 | 9 |
| 창의성 | 7 | 8 | 9 |
| 전달력 | 7 | 9 | 10 |
| 실용성 | 7 | 9 | 9 |
| 총점 | 29점 | 36점 | 37점 |
🏆 가장 우수한 답변: Claude
• 정확성 : Claude는 속담의 원문과 문화적 맥락, 교훈까지 충실히 전달했습니다. ChatGPT는 무난했지만 표현이 단조로웠고, Gemini는 해석은 정확했으나 맥락 설명이 부족했습니다.
• 창의성 : Claude는 예시, 언어 비교, 유래 설명 등을 활용해 내용이 풍부했습니다. Gemini는 전체적으로 정확하게 답했지만, 표현은 다소 평이했고, ChatGPT는 일반적인 수준에 머물렀습니다.
• 전달력 : Claude는 표와 단계별 설명을 통해 이해를 도왔습니다. Gemini는 구성은 단순했고, ChatGPT는 문장이 딱딱해 가독성이 떨어졌습니다.
• 실용성 : Claude는 다양한 콘텐츠에 활용할 수 있을 만큼 완성도가 높았습니다. Gemini는 학습용으로 적합하나 콘텐츠 활용엔 부족했고, ChatGPT는 기초 설명에는 유용하나 실용적 활용을 위해선 보완이 필요했습니다.
이번 글에서는 총 6가지 테스트 중 3가지 항목의 결과를 먼저 소개해 드렸습니다. 다음 글에서는 나머지 항목에 대한 비교 결과도 이어서 소개해 드릴 예정입니다. 이번 테스트를 통해 각 AI 모델이 지닌 강점과 차이를 확인할 수 있었고, 업무 목적에 따라 적절한 모델을 선택하는 것이 중요하다는 점도 확인할 수 있었습니다. 즉, 다양한 모델을 직접 비교하고 유연하게 활용한다면, 더욱 효과적인 AI 사용이 가능하다는 뜻이겠죠. 💡✨
이러한 비교와 선택을 더욱 쉽게 도와주는 도구가 바로 ‘가비아 AI채팅’입니다. 가비아 AI채팅은 ChatGPT, Gemini, Claude 세 가지 모델을 모두 활용할 수 있는 통합 AI 플랫폼으로, 모델별 답변을 한눈에 비교하고 내 업무에 가장 적합한 AI를 직접 선택할 수 있습니다.
가비아 AI채팅이 궁금하시다면, 아래 링크에서 자세한 내용을 확인해 보세요. 🔍
